Introduction
If you spend a lot of time in Linux environment, it is essential that you know where the log files are located, log files duty is to help you troubleshoot an issue. When your systems are running smoothly, take some time to learn and understand the content of various log files, which will help you when there is a crisis and you have to look through the log files to identify the issue. there are plenty of logs to be found: logs for the system, logs for the kernel, for package managers, for the boot process, Apache, MySQL, etc. Most log files can be found in one convenient location “/var/log”. These are all system and service logs, those which you will lean on heavily when there is an issue with your operating system or one of the major services. Fortunately, there are many ways that you can view your system logs, all quite simply executed from the command line.
We are assuming that you have root permission, otherwise, you may start commands with “sudo”.
Log files location
Almost all log files are located in “/var/log/” directory and it’s sub-directories by default, you can use the following command to enter the “log” directory:
cd /var/logNow you can see what is in your log directory, using:
ls -laThe output should be something like the picture below:
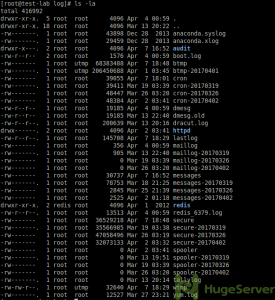
For example, you can see “httpd” directory, it’s pretty specific that you can find your “Apache” log file in that directory.
Reading Log files
There are many commands for reading log files and each one of them has a different purpose.
“cat” Command
You can easily “cat” a log file to simply open it. it’s the easiest way to open a log file but it’s not very handy, Let’s see an example of the output(we are going to cat the “yum.log” as an example)
cat yum.log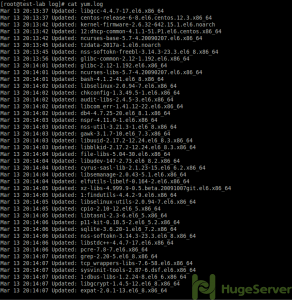
With the cat command, you can see all the log file statically.
“tail” Command
The handiest command that you can use to see your log file is the “tail” command.
If you use the “tail” command with no flags it will show you the last 10 lines of your log file:
tail yum.log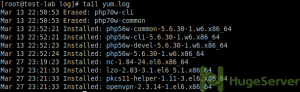
You can see “tail” flags with the command below:
tail --helpThe basic format of “tail” command:
tail [FLAG] [FILENAME]If you want to see the last 100 line of your log file you can execute:
tail -n 100 yourlog.logThe most important flag is the “-f” flag, it will allow you to see your log file live which means the output appended data as the file grows.
tail -f yourlog.log“more” and “less” Command
You can use the “more” command to see your log file page by page and navigate to forward by hitting space:
more yourlog.log“less” is much the same as more command except:
- You can navigate the file up/down line by line with arrow keys.
- You can search for string using “/keyword“.
- And it uses the “vi” editors commands and shortkeys.
less yourlog.log“head” Command
“head” command will show the first 10 lines of your file:
head yourlog.logCombining grep command with other commands
You can add “grep” command if you are seeking for some specific content in your log files such as an IP or a special error:
cat yourlog.log | grep IPtail -f yourlog.log | grep errornameIf you are searching for a specific word in your log file meanwhile you want to see the whole content you may use grep like below:
grep --color [PATTERN] yourlog.log“sort” Command
You can sort the output of your log file with the “sort” command, this command can sort your data by many things:
Using the command below will sort your file alphabetically:
sort yourlog.logIf you add “-r” flag it will sort your data alphabetically but in reverse order:
sort -r yourlog.log“-n” flag will sort your data from lowest number to highest (if your data contains numbers for each item):
sort -n prices.logYou can always use the following command to see all of sort flags:
sort --help“awk” Command
The awk command is a powerful method for processing or analyzing text files, in particular, data files that are organized by lines (rows) and columns.
The basic “awk” format is:
awk 'pattern {action}' input-fileThis means: take each line of the input file if the line contains the pattern apply the action to the line and print the resulting line.
If the pattern is omitted, the action is applied to all lines.
For example:
awk '{ print $5 }' yourlog.logThis statement takes the element of the 5th column of each line and prints it as a line in your shell.
awk '/30/ { print $3 }' yourlog.logThe string between the two slashes (‘/’) is the diameter. In this case, it is just the string “30”. This means if a line contains the string “30”, the system prints out the element in the 3rd column of that line.
The “awk” command can do very complicated things if you want to learn more about “awk” you can read the user manual with the command below:
man awk“uniq” Command
Uniq command is helpful to remove or detect duplicate entries in a file. This section explains few most frequently used uniq command line options that you might find helpful.
The basic “uniq” format is:
uniq [-options]when uniq command is run without any option, it removes duplicate lines and displays unique lines.
uniq yourlog.logThe “-c” flag is to count the occurrence of lines in the file.
uniq -c yourlog.logThis flag will print only unique lines in the file.
uniq -u yourlog.logUseful combo commands
As you might know, you can combine the commands that you saw in the previous sections and make very useful and handy commands. here we are going to point to some of them:
cat yourlog.log |awk -F" " '{print $5}'This command will show you the 5th column that separated with (” “).
cat /var/log/yourlog.log | awk -F" " '{print $1}' | uniq -c | sort -nThis command will show you the first column that separated with and sort them from lowest to highest with the value of occurrence.
Common Linux log files and usage
/var/log/messages : General message and system related stuff/var/log/auth.log : Authentication logs/var/log/kern.log : Kernel logs/var/log/maillog : Mail server logs/var/log/httpd/ : Apache access and error logs directory/var/log/boot.log : System boot log/var/log/mysqld.log : MySQL database server log files/var/log/utmp OR /var/log/wtmp : Login recordsGoing Further
Until now we are just got to know how to read log files, but after the reading section there is a more important thing about log files and it’s how to organize them. if you don’t use an organization solution, you will be facing a lot of problems after a while. In this section, we are going to point to two of the most effective and popular ways to organize your log files.
Log rotation
Logrotate is a tool that can remove, compress and rotate your log files regularly. Logrotare is able to rotate your log files as they grow too large or even you can configure it to do it daily, monthly etc. By default Logrotate invoked daily as a cron job.
Syslog Server
A Syslog server represents a central log monitoring point on a network, to which all kinds of devices including Linux or Windows servers, routers, switches or any other hosts can send their logs over a network. By setting up a Syslog server, you can filter and consolidate logs from different hosts and devices into a single location, so that you can view and archive important log messages more easily.
On most Linux distributions, rsyslog is the standard Syslog daemon that comes pre-installed. Configured in a client/server architecture, rsyslog can play both roles, as a Syslog server rsyslog can gather logs from other devices, and as a Syslog client, rsyslog can transmit its internal logs to a remote Syslog server.